김제시의 초등학교 시설의 흡입력을 계산해 보고자 한다.
먼저 geopandas 와 pandas를 import 하고,
정상적으로 파일이 가져와 지는지 확인해 본다.
import geopandas as gpd
import pandas as pd
shp_file_path = 'C:/Users/이용현/Desktop/프로젝트/241013_데이터/인구/김제 남원 노인 인구 병합.shp'
gdf = gpd.read_file(shp_file_path)
print(gdf.head())
잘 가져와 지는 것을 볼 수 있다.
이제 흡입력을 계산해 보자.
먼저 필요한 데이터를 입력해보면,
1. 접근성 데이터(도시 경계 격자망 형태의 데이터로 각각의 격자의 중심점에서 가장 가까운 시설까지의 거리가 value 필드에 저장됨)
2. 시설 포인트 ( shp파일로 속성에 인프라시설의 속성 분류(field1)와 시설명(field2), 시설 이용 정원(field5)이 입력됨.
데이터를 먼저 vs코드에 불러와 보자.
여기서 주의할 점은 vsc에서 \ 백슬래시는 줄넘김 기호이다. 따라서 윈도우의 파일탐색기에서 경로를 복사해서 붙여 넣을 경우 오류가 뜰 확률이 높다. 따라서 \ 백슬래시를 /일반 슬래시로 모두 바꿔주거나, 'C:\Users\~' 앞에 r을 붙여 r'C:\Users\~'이런식으로 백슬래시가 아니라 기호라는 것을 명령해주어야 한다.
하지만 r을 붙이는 방법은 잘먹히지 않았다.
따라서 나는 전부 일반 슬래시로 바꿔주었으나 더 간편한 방법이 있을 것같아 추가로 서칭 해보아야 할 것 같다.
접근성_data_path = 'C:/Users/이용현/Desktop/프로젝트/241013_데이터/접근성/240416-시설 접근성 동읍면 조인\초등학교 동읍면 조인.shp'
시설_포인트_path = 'C:/Users/이용현/Desktop/프로젝트/241013_데이터/시설포인트/시설 지오코딩 포인트.shp'
접근성_data = gpd.read_file(접근성_data_path)
시설_포인트 = gpd.read_file(시설_포인트_path)
print(접근성_data.head())
print(시설_포인트.head())
위의 두 문단은 접근성의 5행 아래 두문단은 시설 포인트의 5행이다.
gid는 격자의 각고유 번호라고 생각하면 되고 value가 각 격자에서 가까운 시설까지의 거리값이다.
아래의 두문단은 시설포인트의 속성값이고, field1, field2, field5의 값을 활용하면 된다고 위에 적어 놓았다.
먼저 흡입력을 구할때 위의 두 데이터를 활용하는 이유는 접근성 데이터에서 격자로부터 어떤 시설까지의 거리인지 명시되지 않고 단순 거리만 입력되어 있기 때문에 시설의 정원을 알 수 없기 때문이다.
따라서 우리는 접근성 데이터(격자망)와 시설 포인트(포인트) 두 데이터의 지리적 관계를 확인해야 한다.
sjoin()메서드 :
이때 사용할 수 있는 메서드는 sjoin이다.
gpt의 sjoin 메서드 설명을 첨부하겠다.
geopandas의 sjoin() 메서드는 두 개의 GeoDataFrame을 공간적으로 조인(merge)할 때 사용됩니다. 즉, 두 공간 데이터셋의 위치 정보를 기반으로 공통적인 데이터를 합치는 역할을 합니다. 이 메서드는 공간 관계(교차, 포함 등)를 기반으로 데이터를 결합하며, pandas의 일반적인 merge()나 join() 메서드와 비슷하지만, 좌표나 공간 관계를 고려한다는 점이 다릅니다.
geopandas.sjoin(left_df, right_df, how="inner", op="intersects")
주요 매개변수:
- left_df: 첫 번째 GeoDataFrame (기본적으로 공간 조인에서 기준이 되는 데이터).
- right_df: 두 번째 GeoDataFrame (이 데이터셋과의 공간 관계를 바탕으로 결합).
- how: 조인의 방식 (pandas의 merge와 유사).
- "inner": 교집합만 반환 (두 데이터셋에서 공통적인 부분만 결합).
- "left": 왼쪽 데이터셋의 모든 항목을 반환하고, 오른쪽 데이터셋에 해당하는 공간 데이터가 없으면 NaN 값을 채움.
- "right": 오른쪽 데이터셋의 모든 항목을 반환하고, 왼쪽 데이터셋에 해당하는 공간 데이터가 없으면 NaN 값을 채움.
- op: 두 공간 객체 간의 관계를 정의하는 연산자 (기본값: "intersects").
- "intersects": 두 객체가 겹치는지 확인.
- "within": 왼쪽 객체가 오른쪽 객체 내에 있는지 확인.
- "contains": 왼쪽 객체가 오른쪽 객체를 포함하는지 확인.
설명으로 보면 qgis의 벡터도구 중 교차, 합병, 빼기 등의 도구를 사용할 수 있는 것 같다.
다만 우리가 사용해야하는 도구는 격자의 중심점에서 가까운 시설 포인트를 조인 시키는 것.
#위의 기본 활용 코드를 입력해서 사용해보면 오류가 뜨는 것을 알 수 있는데, 이는 op 매개변수가 geopandas가 업데이트 되면서
매개변수가 다양해졌기 때문이다. 따라서
1. **op → predicate**로 변경
geopandas v0.10.0부터는 sjoin()에서 공간적 관계를 지정하는 매개변수가 op에서 **predicate**로 바뀌었습니다. predicate는 두 GeoDataFrame의 공간적 관계를 나타내며, 지원되는 옵션은 다음과 같습니다:
- "intersects": 교차하는 경우
- "contains": 포함하는 경우
- "within": 포함되는 경우
- "touches": 경계가 맞닿는 경우
- "crosses": 교차하는 경우
- "overlaps": 겹치는 경우
- "covers": 덮는 경우
- "covered_by": 덮이는 경우
이렇게 경우를 나눠서 입력해줘야 한다.
어쨋든, 우리는 sjoin 메서드 중에서도 가까운 객체를 찾아 조인시키는 sjoin_nearest() 메서드를 사용해보겠다.
먼저 sjoin메서드를 사용하기 전 두데이터의 좌표계를 맞춰주어야 한다.
그리고 먼저 김제시의 초등학교만 흡입력을 계산해보고자 하기때문에 위의 데이터프레임의 정보를 head()메서드로 확인한 것을 토대로
접근성과 시설포인트에서 김제시를 필터링한다.
그리고 좌표계를 동일하게 세팅한다.
# 초등학교 시설 필터링 (field1을 '초등학교'로 필터링)
초등학교_시설 = 시설_포인트[시설_포인트['field1'] == '초등학교']
# 좌표계 변환 (접근성 데이터에 맞게 초등학교 시설 데이터를 변환)
초등학교_시설 = 초등학교_시설.to_crs(접근성_data.crs)
# 접근성 데이터에서 '도시 이름'이 '김제시'인 데이터만 필터링 (남원시 제거)
접근성_김제시 = 접근성_data[접근성_data['sgg_nm_k'] == '김제시']
# 시설포인트 데이터에서 '필드3'이 '김제시'인 데이터 필터링
김제시_시설 = 초등학교_시설[초등학교_시설['field3'] == '김제시']
흡입력이란 격자의 중심 위치에서 가장 가까운 시설까지의 이용 확률로 (시설 이용 정원/거리^2) 로 계산한다.
시설의 이용 규모가 크고 거리가 가까울수록 이용 확률이 높아 지는 것이다.
이제 '가까운_시설_김제시' 라는 변수를 만들어 sjoin()메서드를 사용해 보겠다.
how='left'. 로 입력해서 접근성 데이터는 모두 가져오고 조인시킬 시설이 없다면 nan을 반환하도록 한다.
distance_col = '거리' 라고 입력해서 가까운 시설을 계산하며 얻은 거리값은 '거리' 라는 변수에 저장한다.
또한 어떤 초등학교를 조인시켰는지 알고 싶으니 field2도 같이 저장해준다. 사실 단순한 열이름 변경이 아닌가 싶다.
정원 열 추가 역시 field5의 값을 열이름 변경과 동시에 계산을 위한 숫자로 변경하는 과정이다.
접근성 value를 value 로 저장해주고
이제 흡입력 열을 계산식으로 입력해주면 아래와 같다.
# 필터링된 시설 데이터를 가까운_시설에 필드3 컬럼과 함께 병합
가까운_시설_김제시 = gpd.sjoin_nearest(접근성_김제시, 김제시_시설, how="left", distance_col="거리")
# 가까운_시설에 필드3 열 추가 (도시 이름)
가까운_시설_김제시['도시 이름'] = 가까운_시설_김제시['field3']
# 초등학교 이름 (field2) 추가
가까운_시설_김제시['초등학교 이름'] = 가까운_시설_김제시['field2'] # 초등학교 세부 이름 (field2)
가까운_시설_김제시['정원'] = pd.to_numeric(가까운_시설_김제시['field5'], errors='coerce') # 정원 (숫자 변환)
# 접근성 value는 접근성 데이터의 거리값임 (흡입력 계산에 사용)
가까운_시설_김제시['접근성 value'] = 가까운_시설_김제시['value'] # 접근성 데이터의 'value' 필드가 거리
# 흡입력 계산 (정원 / 거리^2)
가까운_시설_김제시['흡입력'] = 가까운_시설_김제시.apply(
lambda row: row['정원'] / (row['접근성 value'] ** 2) if row['접근성 value'] > 0 else 0, axis=1
)
# 결과 확인
result_columns = ['geometry', '초등학교 이름','도시 이름', '정원', '접근성 value', '흡입력']
print(가까운_시설_김제시[result_columns].head())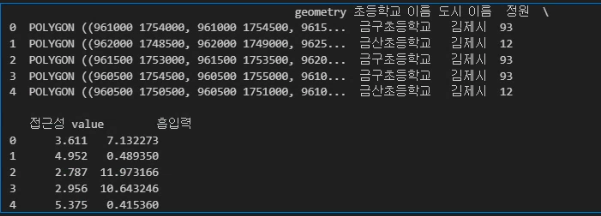
'가까운_시설_김제시' 에 접근성데이터와 가까운 초등학교 시설명과 정원, 계산된 흡입력이 입력되었음을 알 수 있다.
이제 이를 시각화 해보면
(아직 시각화 공부를 하지 못해 일단 gpt에게서 얻은 코드를 입력해보았다.)
import geopandas as gpd
import matplotlib.pyplot as plt
from shapely.geometry import box
# 분석 지역 범위 설정 (접근성 데이터의 전체 경계를 기준으로 그리드 생성)
xmin, ymin, xmax, ymax = 가까운_시설_김제시.total_bounds
# 격자 크기 설정 (여기서는 500m x 500m로 설정)
grid_size = 500
# 격자 생성
rows = int((ymax - ymin) / grid_size)
cols = int((xmax - xmin) / grid_size)
grid_cells = []
for x in range(cols):
for y in range(rows):
x0 = xmin + x * grid_size
y0 = ymin + y * grid_size
x1 = x0 + grid_size
y1 = y0 + grid_size
grid_cells.append(box(x0, y0, x1, y1))
# 그리드를 GeoDataFrame으로 변환
grid = gpd.GeoDataFrame(grid_cells, columns=['geometry'], crs=접근성_data.crs)
# 그리드와 흡입력 데이터 공간 결합 (predicate='intersects' 사용, rsuffix로 충돌 방지)
grid_with_attraction = gpd.sjoin(grid, 가까운_시설_김제시, how="left", predicate="intersects", rsuffix='_시설')
# 흡입력 시각화 (흡입력 값으로 색상 지정)
fig, ax = plt.subplots(figsize=(12, 10))
grid_with_attraction.plot(column='흡입력', cmap='OrRd', legend=True, ax=ax, edgecolor='k', linewidth=0.1)
# 제목 추가
plt.title('초등학교 흡입력 그리드 시각화', fontsize=16)
ax.set_axis_off() # 축 제거
plt.show()

해당 이미지를 얻을 수 있었다.
김제시의 중앙만 높은 값의 흡입력을 갖고 있다.
이를 shp로 추출하여 qgis에 올려보았다.
그리고 내가 전에 qgis에서 분석했던 김제시 초등학교 흡입력 데이터와 비교해보았다.

'가까운_시설_김제시'를 qgis에 올린 모습

이것은 내가 분석했던 김제시 초등학교 흡입력의 모습이다 . 흡입력 열을 심볼로지로 같은 스타일을 입힌 것인데 정확히 일치하는 모습을
볼 수 있다. 제대로 분석이 완료 된 것 같다. 이제
'가까운_시설_김제시_초등학교_흡입력' 이름으로 저장하면 흡입력 계산 끝이다.